
Amazon Redshift Tutorial: Learning Through Puzzles and Examples (Part Two)
 This post is the second part of a three-part series on an Amazon Redshift Data Warehouse. Part One can be found here. Amazon Web Services has made tuning your Redshift Cluster easy. When you use the create table command to create a permanent table or even a temp table you control the table’s distkey and sortkey, and each column’s data type. But make no mistake about it, you should concentrate your tuning efforts on join efficiency. This section will show you how to do just that. I believe in my 25 years of teaching big data that what you are about to learn might be the most monumental information to upgrade your knowledge.
This post is the second part of a three-part series on an Amazon Redshift Data Warehouse. Part One can be found here. Amazon Web Services has made tuning your Redshift Cluster easy. When you use the create table command to create a permanent table or even a temp table you control the table’s distkey and sortkey, and each column’s data type. But make no mistake about it, you should concentrate your tuning efforts on join efficiency. This section will show you how to do just that. I believe in my 25 years of teaching big data that what you are about to learn might be the most monumental information to upgrade your knowledge.
Now, let’s do some exercises to explore table joins, and which of the following joins are more efficient (and why). The number of rows in a table will be a key factor in how you tune tables for joins. Large tables will take a different approach to small tables.
Check out the Data Definition Language (DDL), which means the table CREATE statement for both tables. Look how the data has been spread across the slices for both tables. Compare this page with the next page and choose which page has the best performance when joining the Emp_Tbl with the Dept_Tbl. Give a specific answer for which page you have chosen.

Table Joins: Which Join is More Efficient and Why? This Page or Previous Page?
Check out the Data Definition Language (DDL), which means the table CREATE statement for both tables. Look how the data has been spread across the slices for both tables. Compare this page with the previous page and choose which page has the best performance when joining the Emp_Tbl with the Dept_Tbl. Give a specific answer for which page you have chosen.

Best Choice Because Two Rows Joining Must Physically be on the Same Slice
This example is the best choice for joining because both tables join on the column DeptNo and DeptNo is the DISTKEY for both tables. This means that the matching rows being joined are already on the same slice. Since each slice has their own memory all joining rows must be on the same slice, or Redshift will have to move data around for the join to happen.
 Table Joins: Why is the Example Bad? What Must Redshift Do?
Table Joins: Why is the Example Bad? What Must Redshift Do?
Each Slice has their own memory. Therefore, two rows being joined must physically reside on the same slice. When two tables being joined do not have matching rows co-located on each slice the system will redistribute one or both of the tables by the join column. This has nothing to do with the sortkey column, but everything to do with the distkey of both tables. Redistribution of a table for a join only happens temporarily for the life of the join. The underlying table is copied and then redistributed in memory. Check out what happens on the next page when Redshift redistributes the Emp_Tbl by DeptNo.

Emp_Tbl is Redistributed by Hashing DeptNo Temporarily to Satisfy the Join
In the example below, to get the matching rows on the same slice Amazon Redshift must redistribute the Emp_Tbl by DeptNo instead of its current DISTKEY of EmpNo. This is only done in memory and the redistribution only lasts for the life of this join. This is what you want to avoid. Your design goal is to make sure no data needs redistributed on joins!

Creating a Table with a Distribution Key of ALL
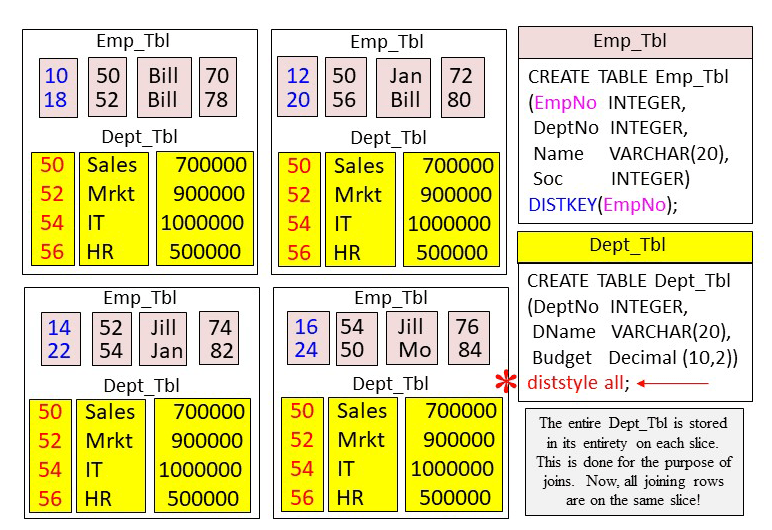
When ALL is selected as the DISTSTYLE the entire table is copied to each slice. This is done so when you join this table to another table the matching rows are guaranteed to be on the same slice! You will use this technique on a smaller table that joins often to a large table. You create the smaller table with a diststyle of ALL and the larger table with a DISKEY. If your smaller table doesn’t join to other tables, you would never use an ALL diststyle. You can see a table’s definition in the PG Table Def data dictionary. Table Joins: Creating a Table with a DISTSTYLE ALL
Table Joins: Creating a Table with a DISTSTYLE ALL
When a table is created with a DISTSTYLE ALL the entire table is stored on each slice. If you have four slices, then the table is duplicated four times. If you have 100 slices, then the table is duplicated 100 times. This seems inefficient, but it is done for smaller tables that need to be joined to larger tables. This is merely a technique to ensure matching rows are co-located.
Creating a Table with an Even Distribution Key
The data always spreads evenly among the slices when your diststyle is even. This is the default distribution if you forget to define a diststyle or distkey. You will only utilize this style if your application needs to read all rows in a table or if you can’t get the data to spread reasonably evenly using any of the columns as a distkey.
 Table Joins: Creating a Table with a DISTSTYLE ALL and a DISTSTYLE EVEN
Table Joins: Creating a Table with a DISTSTYLE ALL and a DISTSTYLE EVEN
When a table is created with a DISTSTYLE ALL the entire table is stored on each slice. If you have four slices, then the table is duplicated four times. If you have 100 slices, then the table is duplicated 100 times. This seems inefficient, but it is done for smaller tables that need to be joined to larger tables. This is merely a technique to ensure matching rows are co-located. This works great when the smaller table joins to a table that is distributed evenly.

Quiz: Fact and Dimension Table Distribution Key Designs
Your mission is to design the tables DISTKEY or DISTSTYLE for the below tables. The Line_Order_Fact_Table is a huge fact table with millions of rows. The Part_Table is the largest Dimension table holding 100,000 rows. The Customer_Table, Supplier_Table, and the Date_Table are small Dimension tables.
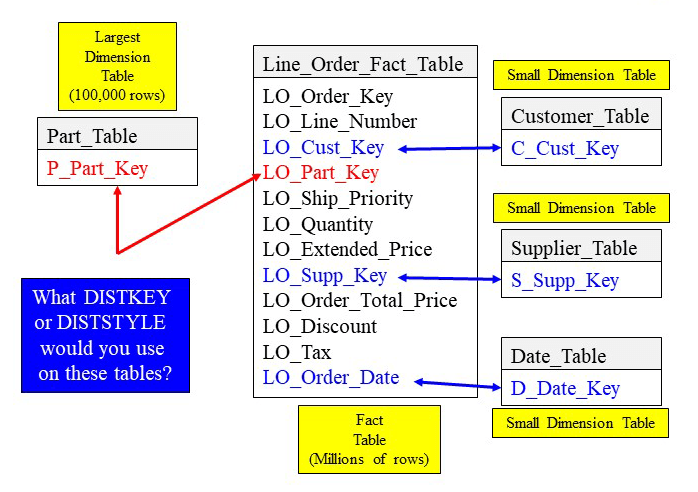
Answer: Fact and Dimension Table Distribution Key Design
The fact table (Line_Order_Fact_Table) is the largest table, but the Part_Table is the largest dimension table. That is why you make Part_Key the distribution key for both tables. Now, when these two tables are joined together, the matching Part_Key rows are already on the same slice. You can then distribute by ALL on the other dimension tables. Each of these tables will have all their rows on each slice. Now, everything that joins to the fact table is co-located!
Improving Performance by Defining a Sort Key
There are three basic reasons to use the sortkey keyword when creating a table. 1) If recent data is queried most frequently, specify the timestamp or date column as the leading column for the sort key. 2) If you do frequent range filtering or equality filtering on one column, specify that column as the sort key. 3) If you frequently join a (dimension) table, specify the join column as the sort key. Below, you can see we have made our sortkey the Order_Date column. Look at how the data is sorted!
 Voila! You now understand Amazon Redshift. If you’d like me (Tera-Tom) to come teach at your organization, please get in touch with the Coffing Data Warehousing team here.
Voila! You now understand Amazon Redshift. If you’d like me (Tera-Tom) to come teach at your organization, please get in touch with the Coffing Data Warehousing team here.