
Amazon Redshift Tutorial: Learning Through Puzzles and Examples (Part One)
 This post is the first part of a series on Amazon Redshift. In this series, we’ll teach you about parallel processing, columnar storage, and how Amazon Redshift is designed. You will also see how Amazon Redshift tables are created, queried, and tuned for performance. Part two posted here!
This post is the first part of a series on Amazon Redshift. In this series, we’ll teach you about parallel processing, columnar storage, and how Amazon Redshift is designed. You will also see how Amazon Redshift tables are created, queried, and tuned for performance. Part two posted here!
Are you looking for one of the best data warehouse solutions for real-time analytics on both small and big data? Your SQL workbench is about to explode. Amazon is different than Teradata. A Teradata system must be tuned by experts before it is ready to perform. Amazon Redshift is a “Load and Go” system, which means you can quickly load data and users are ready to “Go” and query it. With a few important fundamentals, you can design an Amazon Redshift system easily. I won’t show you everything you need to know about Amazon Redshift, but you will be about 90% there. The fun part is that I am going to teach you through a series of puzzles, quizzes, and examples. Some of these puzzles will be tricky to understand at first, but I have color coded the examples for your understanding. You will also most likely miss some of the quizzes, but it won’t take long until you perfect them. Do not hesitate to go over these examples multiple times until you understand them perfectly. You will have outstanding knowledge if you do. Many of the fundamentals you learn here will be a foundation for learning other Massively Parallel Processing systems, especially when the underlying database came from the Open Source Database of PostGres. The Redshift Data Warehouse will soon be one of your favorite data sources and the sample data I have supplied will teach you how it works. Redshift’s petabyte scale linear scalability gets incredible query performance on large data sets with a few tuning concepts.
What is Parallel Processing?
Two guys were having fun on a Saturday night when one said, “I’ve got to go and do my laundry.” The other said, “What!?” The first man explained that if he went to the laundry mat the next morning, he would be lucky to get one machine and be there all day. But if he went on Saturday night, he could get all the machines. Then, he could do all his wash and dry in two hours. Now that’s parallel processing mixed in with a little dry humor!
 Redshift has Linear Scalability
Redshift has Linear Scalability
When Amazon web services entered into the data warehousing and machine learning market, they tool parallel processing even further with their columnar storage vertical partitioning. Amazon is dominating the cloud market with over 80% of the cloud data warehouse business. They make it easy for customers because of their data warehouse service, which means they handle everything for customers concerning the Amazon Redshift Cluster. Redshift was born to be parallel. With each query, a single step is performed in parallel by each slice. A Redshift system consists of a series of slices that work in parallel to store and process data. This design allows a company to start small and grow infinitely. If your Redshift system provides you with an excellent Return On Investment (ROI), then continue to invest by purchasing more nodes (adds additional slices). Most companies start small and continue to grow their ROI from the single step of implementing a Redshift system to millions of dollars in profits. Double your slices and double your speeds….Forever. Lao Tzu was close, but forgot a single letter because Redshift provides a journey of a thousand smiles!

Redshift Quiz – An Example of Placing a Row onto the Proper Slice
The first row is going to slice 1 because the EmpNo value of 10 was hashed (divided by 2), which equates to a row hash 5. The row hash of 5 means to count over 5 buckets in the hash map. The 5th bucket in the hash map has a 1 in it, so this row goes to slice 1. Check out the visual and explanation on the next page.

Fill in the Remaining Rows to the Proper Slice
The first row has been placed on Slice 1 by following our process of hashing the DISTKEY value with the hash formula and then reading the hash map. Your job is to now place all of the rows on the proper slice. The answer is on the next page. Although the real hash formula is not to divide the distribution key by 2, you will soon understand how hashing works. You don’t need to know the real formula, but I want you to understand fundamentally what happens when data is distributed with a math formula. Almost all parallel processing systems use a hash formula for distribution and joins! Fill in the puzzle!
 The Rows have been Placed on the Proper Slice
The Rows have been Placed on the Proper Slice
The first technique you need to understand is that almost all Massively Parallel Processing (MPP) databases use a math formula called a Hash Formula to spread the data among the slices. Notice that the data spread evenly across the slices. This is because there were no duplicate EmpNo values.

Amazon Redshift Breaks Up Rows and Stores them as Columnar
Most traditional databases that came before Amazon Redshift stored rows and rows of data in a data block. Redshift stores data in a Columnar format. This means that each column gets their own data block. Below, we have four slices and each slice has one data block to store the rows. Look below and see how Columnar is really stored.
Columnar storage is designed to store each column in their own data block. Since each row has four columns Amazon Redshift automatically gives each column their own data block. What is important to understand is that an entire row is delivered to the slice, but the slice then places each column in their own data block. This design is done so only the blocks necessary to satisfy a query are placed into memory. Why put all of the data in memory if it is not needed for a particular query. This is why columnar is great for analytics.
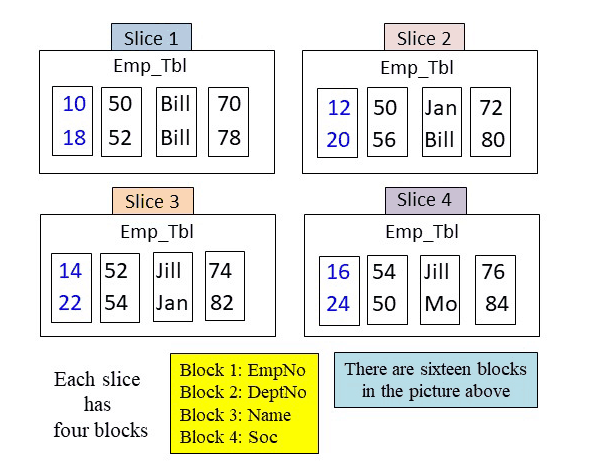
Amazon Redshift Slices Automatically Create Metadata for each Block
Amazon Redshift slices build metadata for each column block for data types that involve numbers and dates. The metadata consists merely of the min/max values in the column block. This allows the optimizer to skip over certain blocks if the query’s WHERE clause falls out of the range of min/max values.
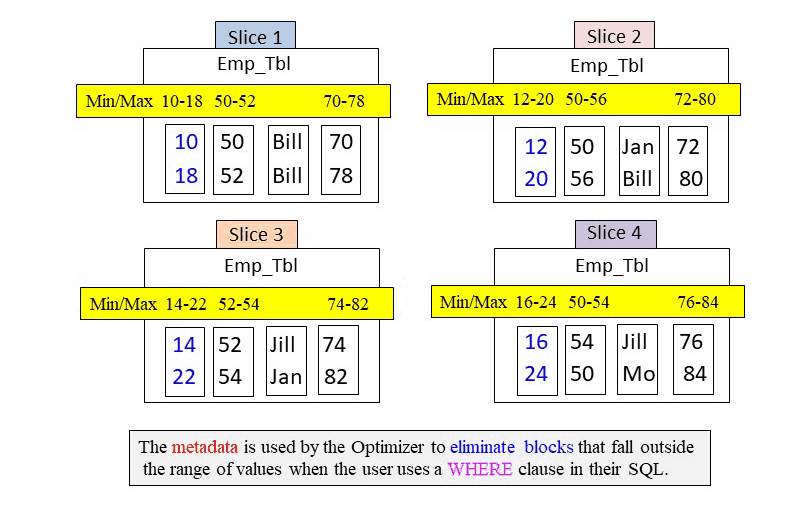 Quiz – How Many Blocks in Total are Read into Memory for this Query?
Quiz – How Many Blocks in Total are Read into Memory for this Query?
Amazon Redshift slices build metadata for each column block for data types that involve numbers and dates. The metadata consists merely of the min/max values in the column block. This allows the optimizer to skip over certain blocks if the query’s WHERE clause falls out of the range of min/max values. Below, you can see the query and the slices. How many blocks in total will be placed into memory?
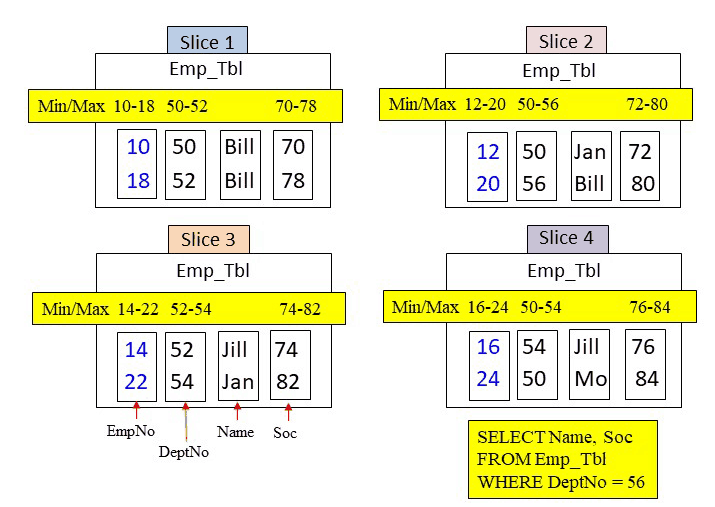
Answer – How Many Blocks in Total are Read into Memory for this Query?
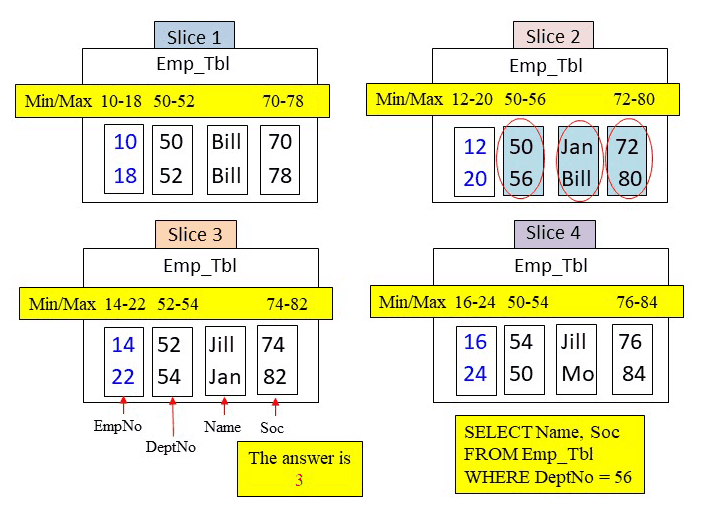
The WHERE clause is looking for a DeptNo = 56. Amazon Redshift will use the metadata to search if a DeptNo block could possibly hold a value of 56. This is how the metadata is used and why it is captured. Performance tuning is all about eliminating blocks on disk from being read into memory. The fewer blocks being moved into memory the faster the query. Below, the metadata for DeptNo shows that only one DeptNo block falls in the min/max range of 56. Therefore, only slice 2 is called upon and it moves in the DeptNo, Name, and Soc column blocks into memory.
Quiz – How Many Blocks in Total are Read into Memory for this Query?
Amazon Redshift slices build metadata for each column block for data types that involve numbers and dates. The metadata consists merely of the min/max values in the column block. This allows the optimizer to skip over certain blocks if the query’s WHERE clause falls out of the range of min/max values. Below, you can see the query and the slices. How many blocks in total will be placed into memory?
Answer – How Many Blocks in Total are Read into Memory for this Query?
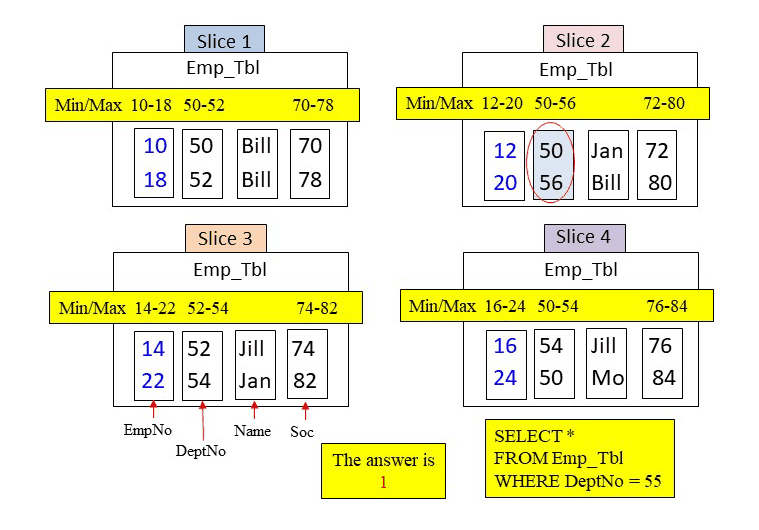
The WHERE clause is looking for a DeptNo = 55. Amazon Redshift will use the metadata to search if a DeptNo block could possibly hold a value of 55. This is how the metadata is used and why it is captured. Performance tuning is all about eliminating blocks on disk from being read into memory. The fewer blocks being moved into memory the faster the query. Below, the metadata for DeptNo shows that only one DeptNo block falls in the min/max range of 55. Therefore, only slice 2 is called upon and it moves in the DeptNo block only to find that DeptNo 55 does not exist. No data is returned.
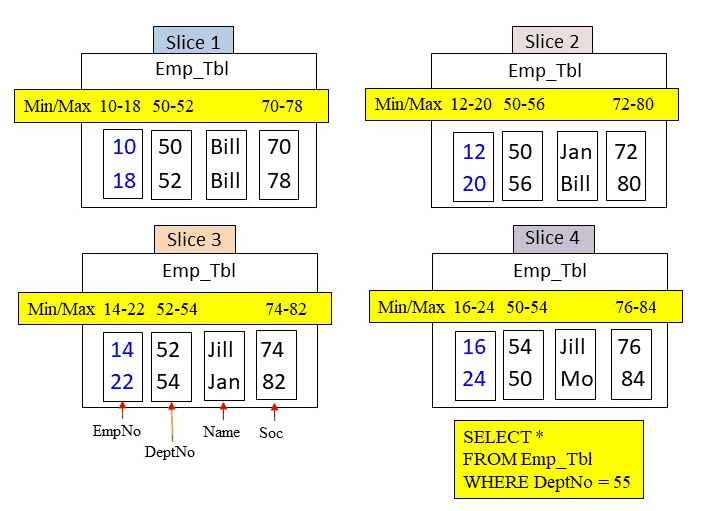
Quiz – How Many Blocks in Total are Read into Memory for this Query?
Amazon Redshift slices build metadata for each column block for data types that involve numbers and dates. The metadata consists merely of the min/max values in the column block. This allows the optimizer to skip over certain blocks if the query’s WHERE clause falls out of the range of min/max values. Below, you can see the query and the slices. How many blocks in total will be placed into memory?
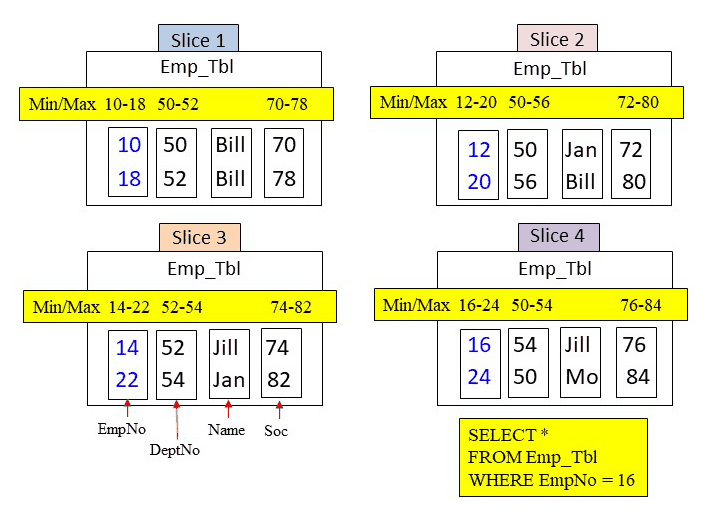
Answer – How Many Blocks in Total are Read into Memory for this Query?
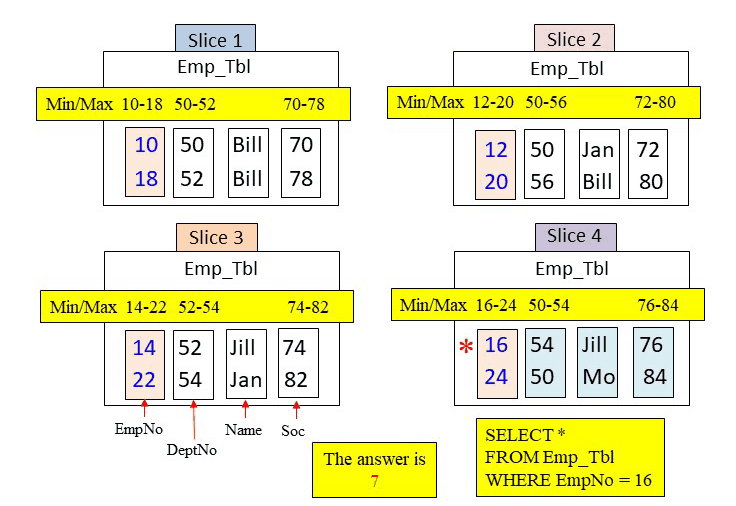
The WHERE clause is looking for an EmpNo = 16. The metadata for EmpNo shows that all EmpNo blocks falls in the min/max range of 16. Therefore, each EmpNo block from each slice must be read into memory. There are four blocks placed into memory for the first check only. Then, after each slice places their EmpNo block in memory only slice 4 found a match. Slice four then places its DeptNo, Name, and Soc blocks into memory to satisfy the query. One row is returned.
The Emp_Tbl CREATE Statement with a DISTKEY of DeptNo and Eight Rows
Below, a table named Emp_Tbl has been created with a DISTKEY on the column DeptNo. Also listed below are the eight rows of the table.
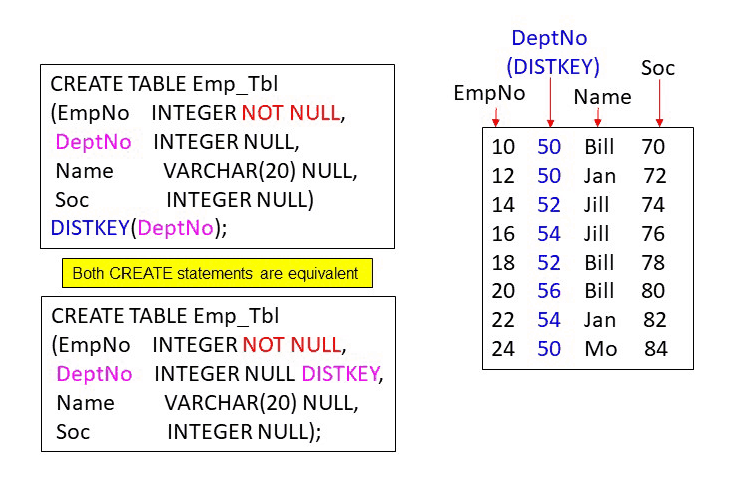
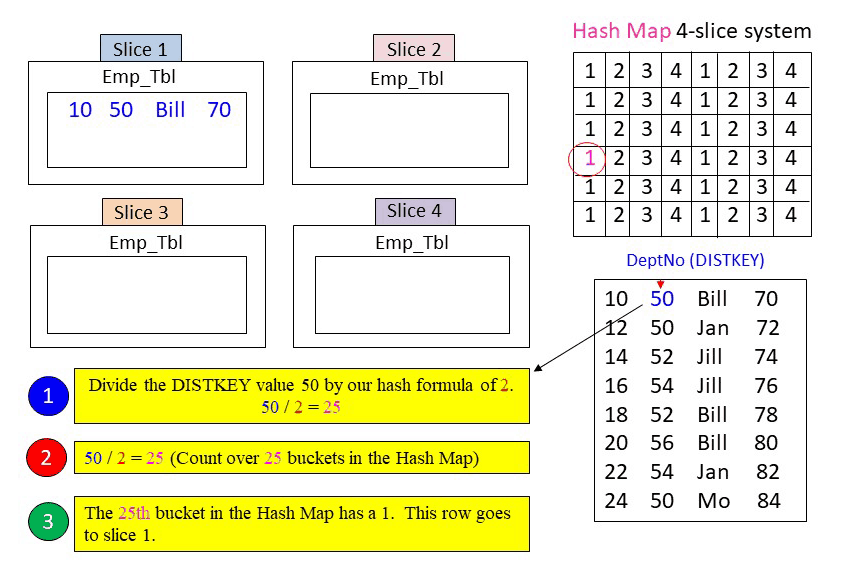
The First Row of the Table has been Placed on the Proper Slice
The first row has been placed on Slice 1 by following our process of hashing the DISTKEY value with the hash formula and then reading the hash map. Your job now is to place the remaining rows on the proper slice. Use your hash formula and divide the Distkey (DeptNo) by 2. Your answer is the result of the hash formula. Take that number and count over to the bucket in the hash map. The number is the bucket will be the slice that the row will be placed.
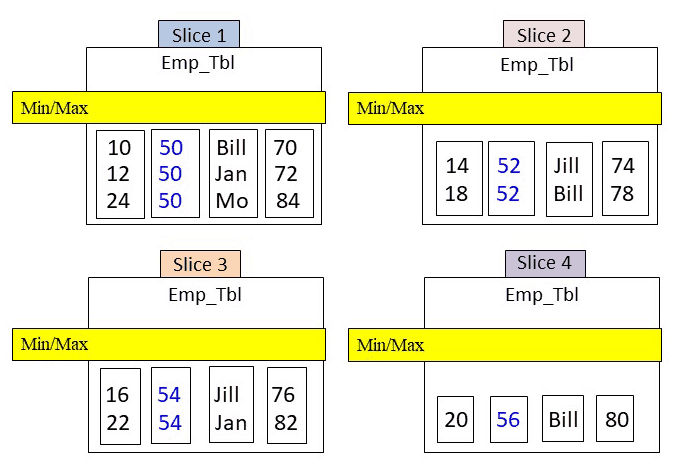
The Rows have been Placed on the Proper Slice
The first technique you need to understand is that almost all Massively Parallel Processing (MPP) databases use a math formula called a Hash Formula to spread the data among the slices. Notice that the data did not spread evenly across the slices. This is because there are duplicate DeptNo values, and all duplicate DeptNo values hash to the same slice.

Amazon Redshift Slices will use Columnar Storage
Columnar storage is designed to store each column in their own data block. Since each row has four columns Amazon Redshift automatically gives each column their own block. What is important to understand is that an entire row is delivered to the slice, but the slice then places each column in their own data block.

Quiz – Can you Place the Metadata in Correctly?
Amazon Redshift slices build metadata for each column block for data types that involve numbers and dates. The metadata consists merely of the min/max values in the column block. This allows the optimizer to skip over certain blocks if the query’s WHERE clause falls out of the range of min/max values.
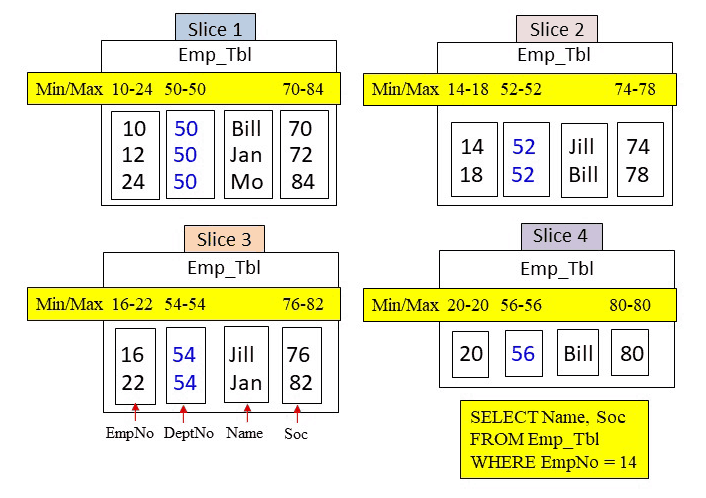
Answer – Can you Place the Metadata in Correctly?
Amazon Redshift slices build metadata for each column block for data types that involve numbers and dates. The metadata consists merely of the min/max values in the column block. This allows the optimizer to skip over certain blocks if the query’s WHERE clause falls out of the range of min/max values. Below, the correct metadata numbers have been placed.

Quiz – How Many Blocks in Total are Read into Memory for this Query?
Amazon Redshift slices build metadata for each column block for data types that involve numbers and dates. The metadata consists merely of the min/max values in the column block. This allows the optimizer to skip over certain blocks if the query’s WHERE clause falls out of the range of min/max values. Below, you can see the query and the slices. How many blocks in total will be placed into memory?
Answer – How Many Blocks in Total are Read into Memory for this Query?
Below, the metadata for EmpNo shows that only two blocks fall in the min/max range of 14. Those two blocks (residing on slices 1 and 2) are read into memory. Then, the system learns that only slice 2 has an EmpNo value = 14. Slice two then places it’s Name and Soc blocks into memory. One row is returned, but four blocks needed to be read into memory.
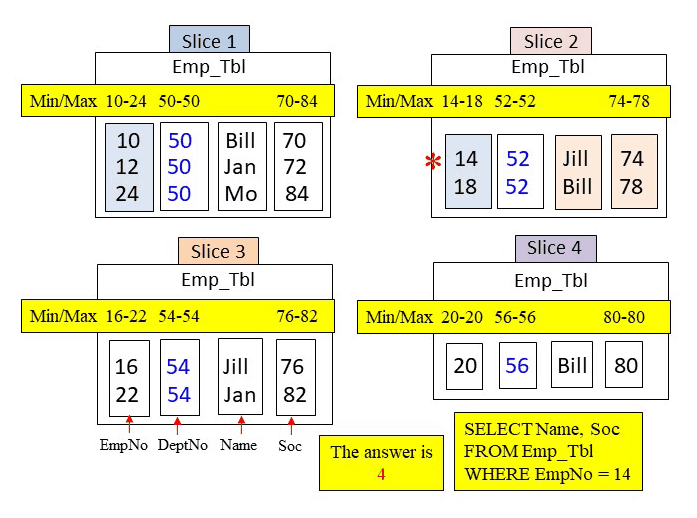
Quiz – How Many Blocks in Total are Read into Memory for this Query?
Amazon Redshift slices build metadata for each column block for data types that involve numbers and dates. The metadata consists merely of the min/max values in the column block. This allows the optimizer to skip over certain blocks if the query’s WHERE clause falls out of the range of min/max values. Below, you can see the query and the slices. How many blocks in total will be placed into memory?
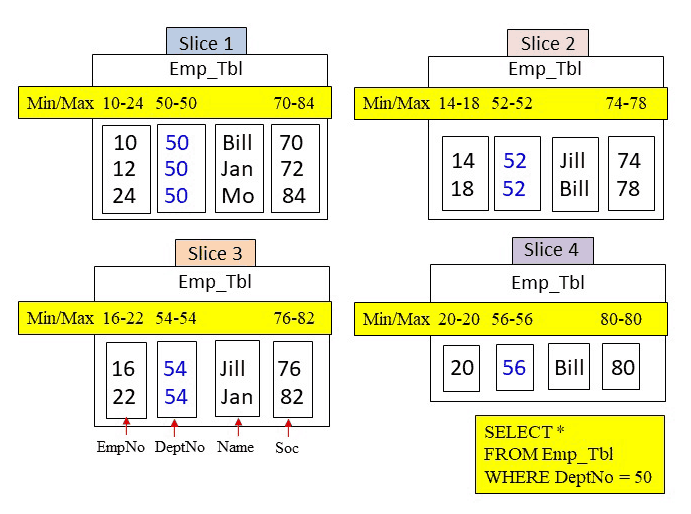
Answer – How Many Blocks in Total are Read into Memory for this Query?
The WHERE clause is looking for a DeptNo = 50. Amazon Redshift will use the metadata to search if a DeptNo block could possibly hold a value of 50. Below, the metadata for DeptNo shows that only one DeptNo block falls in the min/max range of 50. Therefore, only slice 1 is called upon and it moves in the DeptNo block and it finds it has three values of 50. Three rows are returned, but four blocks were read into memory to satisfy the query.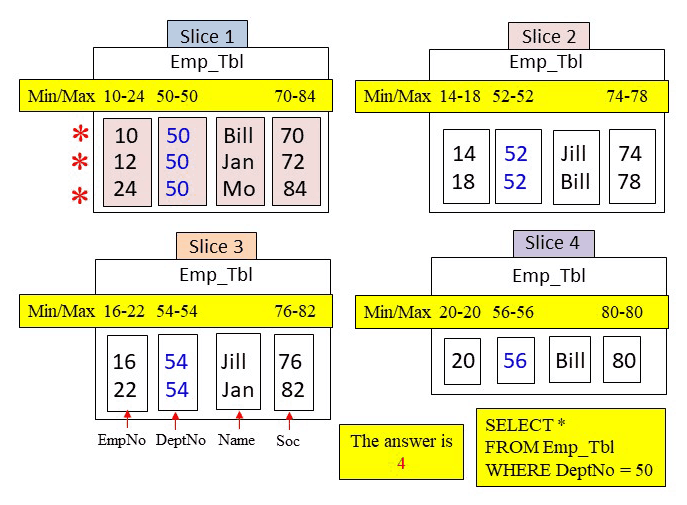
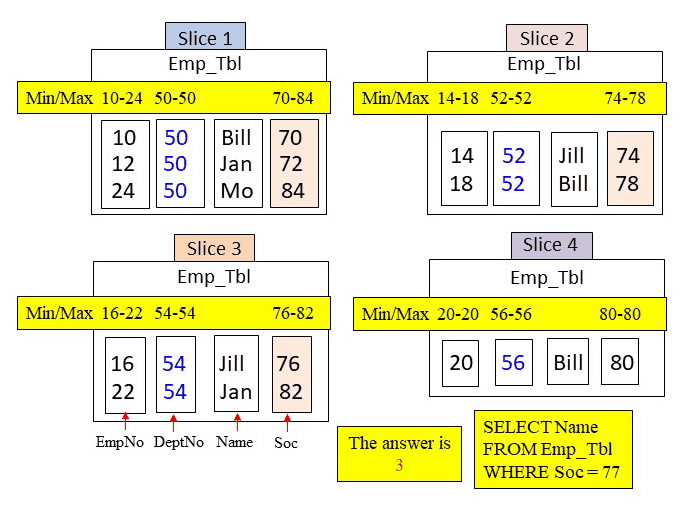
Quiz – How Many Blocks in Total are Read into Memory for this Query?
Amazon Redshift slices build metadata for each column block for data types that involve numbers and dates. The metadata consists merely of the min/max values in the column block. This allows the optimizer to skip over certain blocks if the query’s WHERE clause falls out of the range of min/max values. Below, you can see the query and the slices. How many blocks in total will be placed into memory?
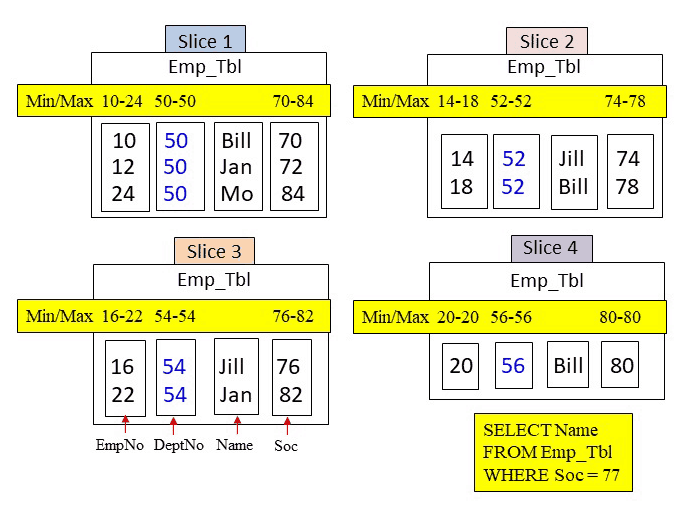
Answer – How Many Blocks in Total are Read into Memory for this Query?
The WHERE clause is looking for a Soc = 77. Amazon Redshift will use the metadata to search if a Soc block could possibly hold a value of 77. Below, the metadata for Soc shows that only three Soc blocks fall in the min/max range of 77. Therefore, slices 1, 2, and 3 are called upon to move in their Soc blocks into memory. The system then finds that there is no Soc of 77 and no rows are returned. However, three blocks were placed in memory.
 Ready for more Amazon Redshift training? Check out Part Two of the Amazon Redshift series. Or, if you’d prefer Tera-Tom to come teach at your organization, contact our team for booking information.
Ready for more Amazon Redshift training? Check out Part Two of the Amazon Redshift series. Or, if you’d prefer Tera-Tom to come teach at your organization, contact our team for booking information.